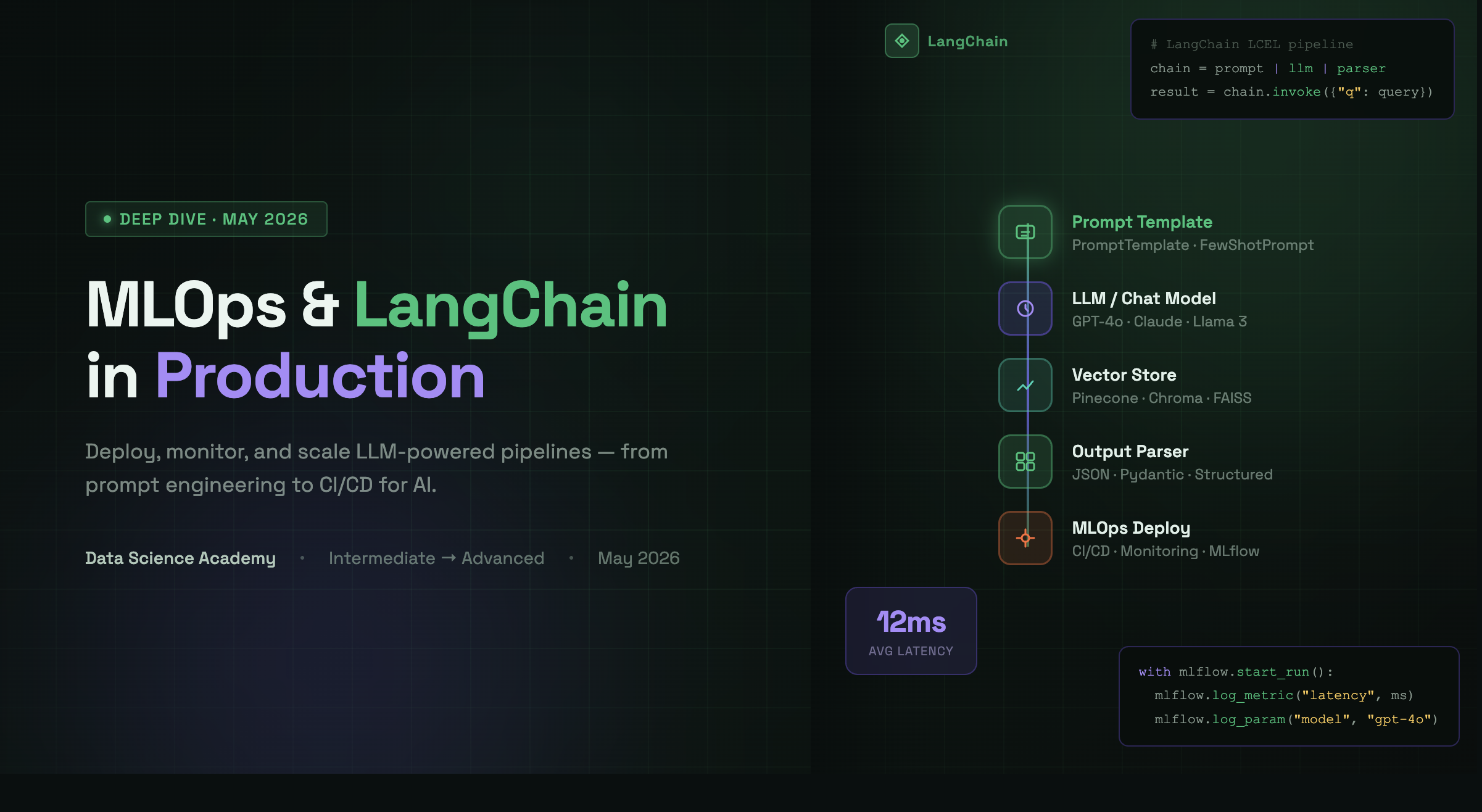
MlOps and LangChain
MLOps & LangChain
From Prompt to Production
Build, orchestrate, and deploy LLM-powered applications — LangChain pipelines, vector databases, CI/CD for models, and real-world MLOps best practices.
Start Learning →⚙️ MLOps Core Concepts
The operational backbone of every production AI system
Why MLOps Exists
Data scientists build models. Engineers ship software. MLOps bridges both worlds. It is the set of practices, tools, and culture that allows machine-learning models to move reliably from a notebook to a live service — and to keep working correctly over time. Without MLOps, 85 % of ML projects never reach production (Gartner). With it, teams deploy ten times faster, catch regressions automatically, and build user trust.
CI/CD for ML
Automate training, testing, and deployment pipelines. Every code push triggers model retraining and evaluation so that only better models reach users.
Model Registry
Track every experiment, compare metrics, and promote winning models to staging and production — all versioned and reproducible with MLflow or W&B.
Monitoring & Observability
Detect data drift, concept drift, and latency regressions in real time. Alert on anomalies before users notice degraded results.
Containerisation
Package models and dependencies into Docker images. Deploy consistently across laptops, staging clusters, and cloud environments.
Orchestration
Use Kubernetes, Kubeflow, or Airflow to schedule training jobs, manage GPU resources, and coordinate multi-step ML pipelines at scale.
Governance & Security
Control who can retrain or promote models, audit predictions for bias, and ensure data lineage is fully traceable for compliance.
🦜 LangChain — Building LLM Applications
The composable framework for production-grade AI pipelines
What is LangChain?
LangChain is an open-source framework that lets developers compose Large Language Model (LLM) calls with tools, memory, and external data sources into reusable, testable chains. Instead of stitching together raw API calls, you declare a pipeline: retrieve context → inject it into a prompt → call the LLM → parse the output → take an action. LangChain handles the boilerplate so you focus on product logic.
🔗 Chains
Compose multiple LLM calls or tool invocations into a single, reusable pipeline with predictable input/output schemas.
🧠 Memory
Give your chatbot short-term and long-term memory — store conversation history in-memory, Redis, or a vector store.
🛠️ Tools & Agents
Equip an LLM with tools like web search, calculators, or SQL queries and let it decide autonomously when to use them.
📄 Document Loaders
Ingest PDFs, websites, Notion pages, and more. Parse and chunk them into pieces ready for embedding and retrieval.
🗄️ Vector Stores
Integrate with Pinecone, Chroma, FAISS, or Weaviate for semantic similarity search at millisecond latency.
⚡ LangChain Expression Language
Compose chains declaratively with LCEL — streaming, batch processing, and async execution out of the box.
# Minimal RAG pipeline with LangChain + OpenAI from langchain_openai import ChatOpenAI, OpenAIEmbeddings from langchain_community.vectorstores import Chroma from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough # 1. Embed & store your documents vectorstore = Chroma.from_documents( documents=docs, embedding=OpenAIEmbeddings() ) retriever = vectorstore.as_retriever(search_kwargs={"k": 4}) # 2. Define a prompt template prompt = ChatPromptTemplate.from_template(""" Answer using only the context below. Context: {context} Question: {question} """) # 3. Compose the chain with LCEL llm = ChatOpenAI(model="gpt-4o", temperature=0) chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | llm ) answer = chain.invoke("What is MLOps?") print(answer.content)
🗄️ RAG & Vector Databases
Make your LLM applications accurate, up-to-date, and hallucination-resistant
Retrieval-Augmented Generation (RAG)
LLMs have a fixed knowledge cutoff and a limited context window. RAG solves both problems by retrieving relevant documents at query time and injecting them into the prompt. The model answers from real, up-to-date evidence rather than from memorised weights — dramatically reducing hallucinations and enabling domain-specific knowledge without expensive fine-tuning.
Ingest & Chunk
Load documents (PDF, HTML, Markdown, SQL), split them into overlapping chunks of ~500 tokens, and attach metadata such as source URL, date, and section title.
Embed
Convert each chunk into a dense vector using an embedding model (OpenAI text-embedding-3-small, Cohere, or a local model). Vectors capture semantic meaning.
Store in Vector DB
Index the vectors in Pinecone, Chroma, Weaviate, or pgvector. Vector databases return the top-k nearest neighbours in milliseconds using ANN algorithms.
Retrieve & Re-rank
At query time, embed the user's question, fetch the top-k chunks, and optionally re-rank them with a cross-encoder to surface the most relevant passages.
Generate & Cite
Inject retrieved context into the LLM prompt. The model grounds its answer in evidence; include source citations so users can verify every claim.
🌍 Real-World Applications
How MLOps and LangChain are reshaping industries
- Enterprise Search: Index internal wikis, Confluence, and SharePoint with RAG so employees get precise answers instead of ten blue links.
- Customer Support Bots: Autonomous agents that read tickets, query order systems, and resolve issues end-to-end without human handoff.
- Code Generation Pipelines: CI/CD-integrated LLM agents that write unit tests, generate PR descriptions, and flag security vulnerabilities.
- Medical & Legal Q&A: Domain-specific RAG over clinical guidelines or case law — auditable, citation-backed answers for professionals.
- Financial Analysis: Agents that pull live data, run calculations, and produce structured reports on earnings calls or SEC filings.
- E-commerce Personalisation: Real-time recommendation chains that combine user history, inventory data, and LLM reasoning to craft bespoke suggestions.
- DevOps Copilots: Chat-based operations — ask in plain English to scale a cluster, roll back a deployment, or diagnose a slow query.
🛠️ Essential Tools & Technologies
The full stack you need to build and ship LLM-powered ML systems
LangChain / LangGraph
Composable chains and stateful multi-agent graphs. LangGraph adds cyclic workflows for complex reasoning loops and human-in-the-loop scenarios.
LangSmith
Observability for LLM applications — trace every chain run, debug prompt failures, evaluate outputs, and run regression test suites automatically.
MLflow
Open-source platform for experiment tracking, model registry, and deployment. Integrates with LangChain for LLM evaluation metrics.
Prefect / Airflow
Orchestrate complex ML workflows: schedule nightly retraining jobs, trigger pipelines on data arrival, and retry failed steps automatically.
Pinecone / Chroma
Managed and local vector databases for semantic search. Pinecone scales to billions of vectors; Chroma is perfect for local prototyping.
AWS SageMaker / Vertex AI
Managed end-to-end ML platforms that handle training infrastructure, model hosting, A/B traffic splitting, and auto-scaling for you.
✅ Key Takeaways
Your action plan for mastering MLOps & LangChain
Build End-to-End First
Ship a tiny, complete pipeline before perfecting any single stage. A rough RAG chatbot in production teaches you more than a perfect notebook model.
Version Everything
Code, data, prompts, and models all change. Track them all — Git for code, DVC or MLflow for data and models, and LangSmith for prompt versions.
Evaluate Rigorously
Define automatic evaluation metrics before you deploy. For LLMs this means faithfulness, answer relevance, and context recall — not just vibes.
Monitor in Production
Set up latency, cost, and quality dashboards from day one. Data and user behaviour drift; your monitoring must catch it before users complain.
Start with RAG, Not Fine-Tuning
RAG is cheaper, faster to iterate, and handles knowledge updates gracefully. Reach for fine-tuning only when RAG has provably hit its ceiling.